Just a quick update on a handful of changes I have made / am making to the site, the first of which is hopefully pretty obvious from the post title! I have been meaning to add a CloudFlare CDN to my WordPress site for a very long time, but like all things which involve a bit of complexity and time to implement, I’ve been putting it off!
My blog was recently suffering quite a few issues caused by the performance of my site host (possible news on that upcoming in the next few weeks). I wanted to both mitigate their performance problems, and generally reduce page times to my site as part of my recent efforts to improve SEO for the site. As many of you may know, Google rank sites higher if they have page load times under about 2000 ms (or 2 seconds to us human folk!)
There are many ways to improve site performance in WordPress, but the one with then biggest impact is to introduce a CDN.
So what is a CDN?
If you haven’t heard of a CDN before, it’s a pretty simple concept. You start by registering DNS for your domain with the CDN provider. After this they sit inline and intercept inbound all requests for content from your site (e.g. images, javascript files, static html, etc) and deliver them from local caches logically and physically closer to the requesting browser. Most CDN providers will have these caches (or POPs aka Points of Presence) all over the globe.
This reduces both outbound bandwidth and server resources used on your web server (otherwise known as an Origin Server), leaving it to get on with serving up dynamic content only. (Yes, technically they can also serve dynamic content, but let’s keep it simple for now!)
Why CloudFlare, and who are the alternatives?
For WordPress blogs, there are a number of well-known alternatives you could choose from (assuming you have little to no budget).
- WordPress project Photon
- Built into the Jetpack, this will cache much of your content to the WordPress cloud servers. This seems to improve performance a bit, but it’s not perfect. The great thing is that it’s insanely easy to enable, with just one check box. Zero hassle implementation!
- Amazon CloudFront
- If you are using AWS, this is a great option, and it’s pretty cheap at about 8-12p per GB of content delivered. You also get 2 million requests and 50GB per month free for the first 12 months on the AWS Free Tier.
- Imperva Incapsula
- If you want the ultimate WAF, I highly recommend this. Their pricing is a bit out of my league for this feature on a personal blog though, so at the free or low cost tiers, CloudFlare worked better for my budget! Ironically if you then move to an enterprise support tier (e.g. for a company site), they are very keenly priced vs some of their competitors.
- CloudFlare
- Superb free and “pro” tier features. Even at free tier you get free SSL, DDoS mitigation and CDN included!
I obviously went for the latter as it gives me options later on, to upgrade to a cloud-based WAF (Web Application Firewall), for a very reasonable price of only $20 per month. This is particularly useful if you are not so good at regularly updating WordPress or plugins as it will protect many of the most common SQL injection or XSS attack types.
What issues did I have implementing CloudFlare?
So far the switch has been pretty easy and smooth, there were just a few considerations, one of which I have resolved, the others I am still working on.
Firstly, CloudFlare is a pure DNS and CDN provider, they do not provide email hosting or forwarding services as standard. By moving my DNS from my existing provider (ZoneEdit) I lost the email forwarding functionality (I’m lazy and just use a catch-all for the domain). Fortunately I found an article by Chris Anthropic on using MailGun as a free alternative.
Second, I am keen to utilise CloudFlare’s free SSL encryption. I have been messing around trying to get either Flex or Full mode working, but have run into a few problems, which I will probably document once resolved! As far as I can tell this is more down to WordPress than CloudFlare!
or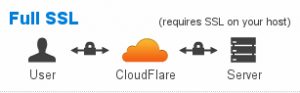
In the mean time, if you go to the HTTPS version of my site you will likely get a few cert errors. These mainly seem to be caused by some objects within pages being HTTP and some HTTPS. This is something I hope to have resolved soon!
Lastly, the massively improved page load times have (as per the theory of constraints) uncovered the next bottlenecks in my system, which mainly seem to revolve around certain plugins I’m using for WordPress. If you want to check your own blog, simply open Chrome developer tools, navigate to the Network Tab, then refresh one of your pages for a very useful picture of the load times on your pages and every object within them:
The Result
So what is the result of all this effort? I seem to have reduced my average page load time down from 5-10 seconds, into the 2.5-3 second range for most pages, and much of that is background loading (i.e. most content appears almost instantly)! I will be working on those plugins to try to get everything under the 2000ms time frame over the next few weeks…
If you aren’t already using a CDN for your WordPress blog (other blog providers are available!), I highly recommend you check out CloudFlare!






 RSS – Posts
RSS – Posts