



A couple of months ago I wrote a post entitled Scale-Out. Distributed. Whatever the Name, it’s the Future of Computing.
Taking the concept a step further, I recently started thinking about other elements in IT which are moving in that direction; not just applications and storage, but underlying infrastructure and management elements too.
Then it dawned on me that this really is not a new thing… we’ve been taking this approach for years! Technologies like VMware vSphere, have enabled us to become trusting, almost presumptuous, that we can add resources as we need them; increasing the shared pool transparently and enabling us to continue to service requirements, whilst eliminating downtime. (You can even use them to scale up on-the-fly if you really have to!)
The current breed of infrastructure engineers and startups have grown up in this era and the great thing is that this has now become part of their DNA! Typically, no longer are solutions designed from scratch to be scale-up in nature; hitting some artificial limit in capacity or having to scale specific elements of a solution to avoid nasty bottlenecks.
Instead, infrastructure is being designed to scale-out natively; distributed architectures, balancing workloads and metadata evenly across platforms. This has the added benefit, of course, of making them more resilient to failure of individual components.
Backup isn’t Sexy, but it’s Necessary
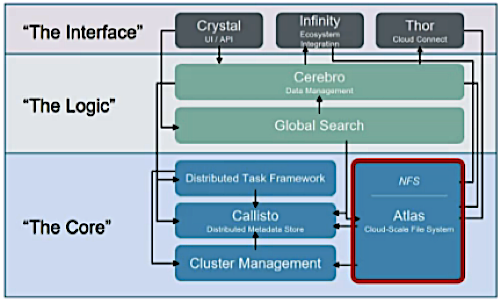
One great example of this new architecture paradigm (drink!), is Rubrik, a startup in the backup space who we met at Tech Field Day 12. Their home-grown distributed file system, distributed metadata, built in off-site replication and global namespace, provide a massively scalable and resilient backup system.
All of the roles from a traditional backup solution (such as backup proxies/media servers/metadata servers, etc) are now rolled into a single, scale-out platform. As I seem to find myself saying more and more often these days, KISS personified!
With shrinking IT teams, I commonly find that companies are willing to trade budget for time savings. Utilising a simple, policy-driven management interface and enabling off-site replication to be done over-the-wire, has a lot of benefits to operational time!
As an added bonus, it can even replicate out to S3, Blob and NFS targets, to give even more options for off-site replication. Of course, a big fat pipe to the internet will cost you more each month; though you’re probably investing in that anyway, to meet your employee’s peak lunchtime demand for facebook and youtube! 🙂
Much like any complex machine, under the hood, Rubrik is pretty impressive. There is a masterless cluster management solution, multi-tier flash and disk for performance, and a clever redirect-on-write snapshot chain algorithm, which minimises capacity utilisation whilst providing very granular restores.
The key thing here, though, is we don’t really care; we are a consumer society who just wants things to work, as we have more exciting things than backup to worry about!
TLDR;
We have enough complexity in IT these days without having to worry about backup. I would say that the simple to manage, scale-out solution from Rubrik is certainly worth considering as part of any PoC or RFP! 🙂
Further Info
You can catch the full Rubrik session at the link below:
Rubrik Presents at Tech Field Day 12
Further Reading
Some of the other TFD delegates had their own takes on the presentation we saw. Check them out here:
- John White – Backups suck, Rubrik does not
- Mike Preston – The Atlas File System – The foundation of the Rubrik Platform
Disclaimer: My flights, accommodation, meals, etc at Tech Field Day 12 were provided by Tech Field Day, but there was no expectation or request for me to write about any of the vendors products or services.
 RSS – Posts
RSS – Posts