



There can be little doubt these days, that the future of the storage industry for primary transactional workloads is All Flash. Finito, that ship has sailed, the door is closed, the game is over, [Insert your preferred analogy here].
Now I can talk about the awesomeness of All Flash until the cows come home, but the truth is that flash is not now, and may never be as inexpensive for bulk storage as spinning rust! I say may as technologies like 3D NAND are changing the economics for flash systems. Either way, I think it will still be a long time before an 8TB flash device is cheaper than 8TB of spindle. This is especially true for storing content which does not easily dedupe or compress, such as the two key types of unstructured data which are exponentially driving global storage capacities through the roof year on year; images and video.
With that in mind, what do we do with all of our secondary data? It is still critical to our businesses from a durability and often availability standpoint, but it doesn’t usually have the same performance characteristics as primary storage. Typically it’s also the data which consumes the vast majority of our capacity!

Accounting needs to hold onto at leat 7 years of their data, nobody in the world ever really deletes emails these days (whether you realise or not, your sysadmin is probably archiving all of yours in case you do something naughty, tut tut!), and woe betide you if you try to delete any of the old marketing content which has been filling up your arrays for years! A number of my customers are also seeing this data growing at exponential rates, often far exceeding business forecasts.
Looking at the secondary storage market from my personal perspective, I would probably break it down into a few broad groups of requirements:
- Lower performance “primary” data
- Dev/test data
- Backup and archive data
As planning for capacity is becoming harder, and business needs are changing almost by the day, I am definitely leaning more towards scale-out solutions for all three of these use cases nowadays. Upfront costs are reduced and I have the ability to pay as I grow, whilst increasing performance linearly with capacity. To me, this is a key for any secondary storage platform.
One of the vendors we visited at SFD8, Cohesity, actually targets both of these workload types with their solution, and I believe they are a prime example of where the non-AFA part of the storage industry will move in the long term.
The company came out of stealth last summer and was founded by Mohit Aron, a rather clever chap with a background in distributed file systems. Part of the team who wrote the Google File System, he went on to co-found Nutanix as well, so his CV doesn’t read too bad at all!
Their scale-out solution utilises the now ubiquitous 2u, 4-node rack appliance physical model, with 96TB of HDDs and a quite reasonable 6TB of SSD, for which you can expect to pay an all-in price of about $80-100k after discount. It can all be managed via the console, or a REST API.

2u or not 2u? That is the question…
That stuff is all a bit blah blah blah though of course! What really interested me is that Cohesity aim to make their platform infinitely and incrementally scalable; quite a bold vision and statement indeed! They do some very clever work around distributing data across their system, whilst achieving a shared-nothing architecture with a strongly consistent (as opposed to eventually consistent), 2-phase commit file system. Performance is achieved by first caching data on the SSD tier, then de-staging this sequentially to HDD.
I suspect the solution being infinitely scalable will be difficult to achieve, if only because you will almost certainly end up bottlenecking at the networking tier (cue boos and jeers from my wet string-loving colleagues). In reality most customers don’t need infinite as this just creates one massive fault domain. Perhaps a better aim would be to be able to scale massively, but cluster into large pods (perhaps by layer 2 domain) and be able to intelligently spread or replicate data across these fault domains for customers with extreme durability requirements?
Lastly they have a load of built-in data protection features in the initial release, including instant restore, and file level restore which is achieved by cracking open VMDKs for you and extracting the data you need. Mature features, such as SQL or Exchange object level integration, will come later.
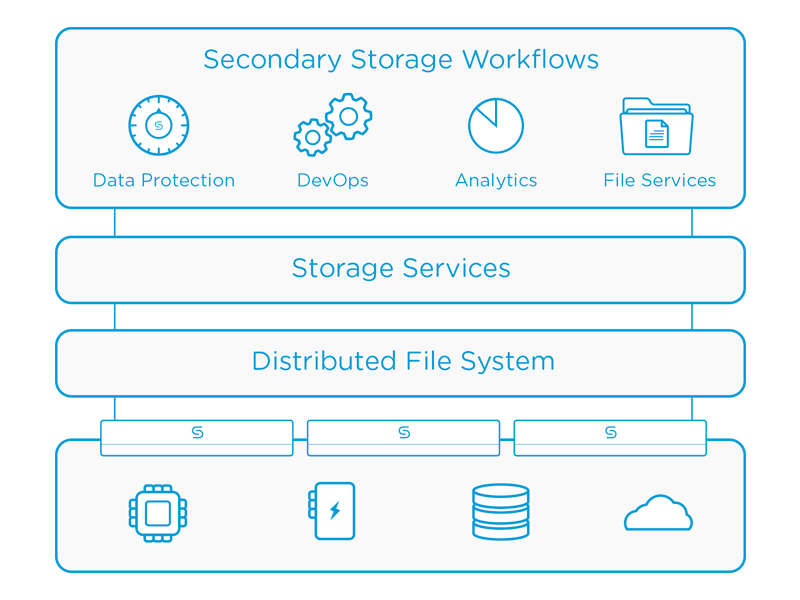
Cohesity Architecture
As you might have guessed, Cohesity’s initial release appeared to be just that; an early release with a reasonable number of features on day one. Not yet the polished article, but plenty of potential! They have already begun to build on this with the second release of their OASIS software (Open Architecture for Scalable Intelligent Storage), and I am pleased to say that next week we get to go back and visit Cohesity at Storage Field Day 9 to discuss all of the new bells and whistles!
Watch this space! 🙂
To catch the presentations from Cohesity as SFD8, you can find them here:
http://techfieldday.com/companies/cohesity/
Further Reading
I would say that more than any other session at SFD8, the Cohesity session generated quite a bit of debate and interest among the guys. Check out some of their posts here:
- Scott D. Lowe – So, What is Secondary Storage Cohesity-Style?
- Mark May – Redefining Secondary Storage
- Dan Frith – Cohesity – There’s more to this than just “Secondary Storage”
- Enrico Signoretti – We are entering the Data-aware infrastructure era
- Jon Klaus – Cohesity is changing the definition of secondary storage
- Vipin V.K. – Cohesity – Secondary storage consolidation
- Josh De Jong – Cohesity – Scale-Out Secondary Storage
Disclaimer/Disclosure: My flights, accommodation, meals, etc, at Storage Field Day 8 were provided by Tech Field Day, but there was no expectation or request for me to write about any of the vendors products or services and I was not compensated in any way for my time at the event.
 RSS – Posts
RSS – Posts