



A rose by any other name would smell as sweet?
We might all agree that this is most definitely the case, but in the technology industry we have a problem, and it was highlighted across a number of the sessions we attended at Storage Field Day 9 this week.
Specifically, the use of certain terms to describe technology features, when the specific implementations are very different, and have potentially very different outcomes. This is becoming more and more of a problem across the industry as similar features are being “RFP checkboxed” as the same, when in reality they are not.
Words mean things! #SFD9
— Justin Warren (@jpwarren) March 17, 2016
For example most of the vendors we saw support deduplication in one form or another, and in many cases there was a significant use of the word “inline”.
What do we mean by “inline deduplication”, and what impact to performance can this have?
One of the other delegates at SFD9, W Curtis Preston, had very strong opinions on this, which I am generally inclined to agree with!
UPDATE 08/04/2016: Curtis has recently published an article detailing his thoughts here.
If a write hits the system and is deduplicated prior to being written to its final non-volatile media, be it flash or disk, then it can generally be considered as inline.
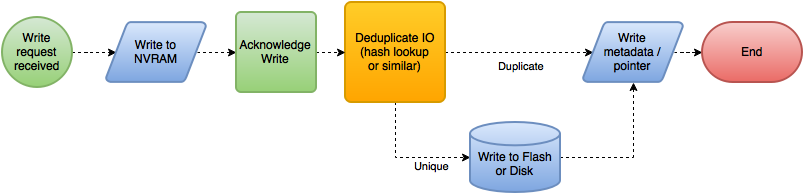
Inline Deduplication
If deduplication is running in hardware (for example as 3PAR do in their Gen4+ ASIC), the deduplication process has minimal overhead on the system, and by not needing to send all writes to the back end storage it can actually improve performance overall, even under sustained high throughput where it can actually improve it by reducing back end writes.
Most non-inline deduplication would typically be referred to as “post-process”, and as a general rule are either run on a schedule or as a lower priority 24/7 system maintenance task. It can also run immediately after the write has gone to disk. This is still post-process, not inline.
It’s worth noting that any of these post-process methods can potentially have an impact on back-end capacity management, as dumping large quantities of data onto a system can temporarily spike capacity utilisation until the dedupe process has time to work its magic and increase storage efficiency. Not ideal if your storage capacity is approaching critical.

In addition, the block has been written to an NVRAM device which should protect it from power loss etc, but the problem we have is that cache is an expensive and finite resource. As such, by throwing a sustained number of IOs at the system, you end up potentially filling up that cache/NVRAM faster than the IOs can be flushed and deduplicated, which is exacerbated by the fact that post-process dedupe generates yet more IOPS on the back end storage (by as much as 2-3x compared to the original write!). The cumulative effect causes IO to back up in the system like a dodgy toilet, thereby increasing latency and reducing your maximum capable IOPS from the system.
Worse still, in some vendor implementations, when system performance is maxed out deduplication in the IO path is dropped altogether, and inbound data is dumped out to disk as fast as possible. Then is then post-processed later, but this could obviously leave you in a bit of a hole again if you are at high capacity utilisation.
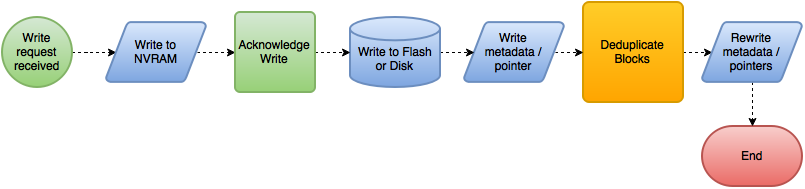
Post-Process Deduplication
None of this is likely to kick in for the vast majority of customers as they will probably have workloads generating tens of thousands of IOPS, or maybe low hundreds of thousands on aggregate. As such, for most modern systems and mixed workloads, this is unlikely to be a huge problem. However, when you have a use case which is pushing your array or HCI solution to its maximum capability, this can potentially have a significant impact on performance as described above.
[HCI – yet another misappropriated computing acronym, but I’ll let that one slide for now and move on!]
VMware VSAN Deduplication
In the case of one of one of the vendors we saw, VMware, they joked that because of the fact that they initially write to the caching flash tier prior to deduplication, they spent more time arguing over whether it was valid to call this inline than it took them to actually develop the feature! In their case, they have been open enough not to call it “inline” but instead “nearline”.
In part this is because they are always written to a flash device prior to dedupe, but also because not all of the writes to their caching tier actually get sent to the capacity tier. In fact some may live out their entire existence in an non-deduplicated state in flash cache.

I applaud VMware for their attempt to avoid jumping on the inline bandwagon, though it would have perhaps been better to use a term which doesn’t already mean something completely different in the context of storage! 🙂
You can catch the full VMware session at the link below – it’s well worth a watch!
VMware Storage Presents at Storage Field Day 9
Further Reading
Some of the other SFD9 delegates and VMware staffers had their own takes on the presentation we saw. Check them out here:
- Enrico Signoretti – VMware VSAN, When good enough becomes very good
- Richard Arnold – Will VSAN be THE SAN?
- Duncan Epping – Want to hear all about VSAN 6.2? Watch the #SFD9 recordings!
- W Curtis Preston – Not all “Inline” Dedupe is actually Inline – and it matters
Disclaimer/Disclosure: My flights, accommodation, meals, etc, at Storage Field Day 9 were provided by Tech Field Day, but there was no expectation or request for me to write about any of the vendors products or services and I was not compensated in any way for my time at the event.
 RSS – Posts
RSS – Posts