With the release of v2.0 of their OASIS platform, as presented as Storage Field Day 9 recently, Cohesity’s development team have continued churn out new features and data services at a significant rate. It seems that they are now accelerating towards the cloud (or should that be The Cloud?) with a raft of cloud integration features announced today!
There are three key new features included as part of this, called CloudArchive, CloudTier and CloudReplicate respectively, all of which pretty much do exactly what it says on the tin!
CloudArchive is a feature which allows you to archive datasets to the cloud (duh!), specifically onto Google Nearline, Azure, and Amazon S3. This would be most useful for things like long term retention of backups without taking up space on your primary platform.
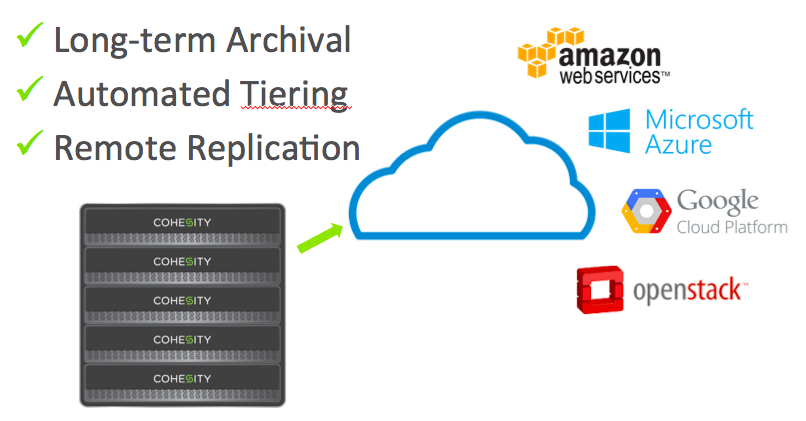
CloudTier extends on-premises storage, allowing you to use cloud storage as a cold tier, moving your least used blocks out. If you are like me, you like to understand how these things work down deep in the guts! Mohit Aron, Founder & CEO of Cohesity, kindly provided Tekhead.it with this easy to understand explanation on their file and tiering system:
NFS/SMB files are mapped to objects in our system – which we call blobs. Each blob consists though of small pieces – which we call chunks. Chunks are variable sized – approximately ranging from 8K-16K. The variable size is due to deduplication – we do variable length deduplication.
The storage of the chunks [is] done by a completely different component. We group chunks together into what we call a chunkfile – which is approximately 8MB in size. When we store a chunkfile on-prem, it is a file on Linux. But when we put it in the cloud, it becomes an S3 object.
Chunkfiles are the units of tiering – we’ll move around chunkfiles based on their hotness.
So there you have it folks; chunkfile hotness is the key to Cohesity’s very cool new tiering technology! I love it!

With the chunkfiles set at 8mb this seems like a sensible size for moving large quantities of data back and forth to the cloud with minimal overhead. With a reasonable internet connection in place, it should still be possible to recall a “cool” chunk without too much additional latency, even if your application does require it in a hurry.
You can find out more information about these two services on a new video they have just published to their youtube channel.
The final feature, which is of most interest to me is called CloudReplicate, though this is not yet ready for release and I am keen to find out more as information becomes available. With CloudReplicate, Cohesity has made the bold decision to allow customers to run a software only edition of their solution in your cloud of choice, with native replication from their on premises appliances, paving the way to true hybrid cloud, or even simply providing a very clean DR strategy.
This solution is based on their native on-premises replication technology, and as such will support multiple replication topologies, e.g. 1-to-many, many-to-1, many-to-many, etc, providing numerous simple or complex DR and replication strategies to meet multiple use cases.

It could be argued that the new solution potentially provides their customers with an easy onramp to the cloud in a few years… I would say that anyone making an investment in Cohesity today is likely to continue to use their products for some time, and between now and then Cohesity will have the time to significantly grow their customer base and market share, even if it means enabling a few customers to move away from on-prem down the line.
I have to say that once again Cohesity have impressed with their vision and speedy development efforts. If they can back this with increase sales to match, their future certainly looks rosy!
Disclaimer/Disclosure: My flights, accommodation, meals, etc, at Storage Field Day 9 were provided by Tech Field Day, but there was no expectation or request for me to write about any of the vendors products or services and I was not compensated in any way for my time at the event.







 RSS – Posts
RSS – Posts