



Continuing in this series of blog posts taking a bit of a “warts and all” view of a few Amazon AWS features, below is another tip for designing and implementing solutions on Amazon AWS. In this case, Scale-Up Patching of Auto-Scaling Groups (ASGs) and a couple of wee bonuses about Dark Launch techniques.
For the first post in this series with a bit of background on where it all originated from, see here:
Amazon #AWS Tips and Gotchas – Part 1
For more posts in this series, see here:
Index of AWS Tips and Gotchas
19. AWS Tips and Gotchas – Part 9 – Scale-Up Patching in ASGs
Very quick tip on Auto Scaling Groups this week, courtesy of an awesome session I attended at the AWS User Group UK (London) last week on DevOps, presented by Chris Turvil from The Trainline.
Assuming you need to just do a code release to an existing farm of servers running in an ASG, and you aren’t planning anything complex such as a DB schema update, you can use a technique called “Scale-Up Patching”. I hadn’t heard the term before, but it’s actually incredibly simple, but very effective! There are a couple of methods you might use, depending on how you deliver your code, but the technique is the same; make your new code or image live, double the minimum size of your ASG, then halve it! Job done! So how does this work?
So how does this work?
If you have looked into the detail of ASGs, assuming you have roughly even instances spread over multiple AZs then when an ASG shrinks / scales down, the oldest EC2 instances are killed first. For more detail on the exact rules, see here.
If you double the size of your current number of instances, all of the new instances will be deployed with your new code version. This leaves you with a farm of 50% vOld and 50% vNew. When you then tell the ASG to scale to the original size, it will obviously kill off all of the vOld instances, leaving your entire farm upgraded. If you found an issue and had to roll back, you simply rinse and repeat the same exercise! How brilliant is that?!
This process will work exactly the same regardless of whether you deploy your code via updated AMIs each time, or simply post-boot using a user-data script which pulls your source from a bucket, repo, or similar. Either way, the result is the same and infinitely repeatable!
The one counter to this which a colleague of mine brought up, is that you are explicitly depending on a specific feature of AWS always functioning in the same way and not changing in the future. An alternative might be to deploy in a blue-green setup with independent ELBs and instances. You then simply failover using Route53, either all in one go or using weighted routing for a canary release process. Funnily enough, AWS released a white paper on exactly that subject a couple of months ago:
Blue/Green Deployments on AWS Whitepaper
They also cover the scale-up patching method in detail from page 17 of the whitepaper.
Brucie Bonus One – Deployment Dictionary
Incidentally, you can actually deploy said code, without it actually going live immediately, by using methods called “Dark Launch Techniques”. As the name suggests, this separates code deployment from feature launches. You pre-release your code into production, but you simply don’t toggle it on for anyone (or everyone) at first. You can then either toggle it on for everyone, or even better, smaller canary groups. Web-scale companies such as Netflix, Facebook and Google have been doing this for many years!
This process then completely avoids the panic-inducing impact of deploying a large new code release whilst simultaneously having that code go live and ramping up utilisation at the same time!

Combining dark launch methods with scale-up patching or blue/green deployments should lead to a few less grey hairs in the long run, that’s for sure!
For more info, see the following overview:
What is a dark launch in terms of continuous delivery of software?
Brucie Bonus Two – Environment Manager
Lastly, a bit of interesting news which also came from The Trainline is that they have open sourced their own internal deployment tool, they call Environment Manager.
With an AngularJS front end, and a Node.js back end, it’s a home-grown continuous deployment tool which includes a self-service portal, REST APIs, and a number of operational governance features. The governance elements include a feature which prevents rogue developers deploying anything which hasn’t already been defined in the central service catalogue.
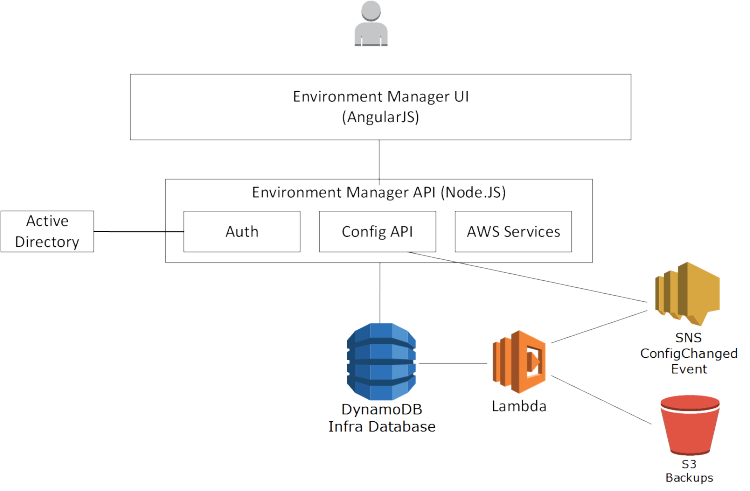
You can check out Environment Manager on GitHub:
https://trainline.github.io/environment-manager
Want More AWS Tips and Gotchas?
Find more posts in this series here:
Index of AWS Tips and Gotchas
Amazon AWS Tips and Gotchas – Part 10 – EFS (Elastic File System)
 RSS – Posts
RSS – Posts